Evaluation
Your autonomous engineer needs to know what’s broken to fix it. Evaluation provides comprehensive quality assessment that powers autonomous issue detection and fix generation.
The Problem: Manual Quality Review Doesn’t Scale
2am failures wake you up. Your AI handles thousands of interactions daily. You suspect quality is declining, but manually reviewing responses is overwhelming. You check 50 conversations, find issues, and wonder about the other 4,950 interactions you didn’t see.
Manual evaluation doesn’t scale. By the time you notice problems, they’ve already impacted users. You end up playing whack-a-mole with quality issues instead of systematically improving your AI.
Your autonomous engineer solves this by using AI to evaluate AI—at scale, consistently, and with focused insights that power automatic issue detection and fix generation.
Your autonomous engineer evaluates every interaction, detects quality patterns, and generates targeted fixes based on comprehensive quality data.
How Evaluation Powers Your Autonomous Engineer
Issue Detection: By monitoring quality scores continuously, your autonomous engineer identifies when performance drops and what patterns indicate problems.
Root Cause Analysis: Detailed evaluation data helps your autonomous engineer understand whether issues stem from prompt problems, logic errors, or missing context.
Fix Validation: Before creating pull requests, your autonomous engineer tests improvements against evaluation data to ensure fixes actually work.
Continuous Learning: As fixes get deployed, new evaluation data shows their effectiveness, helping your autonomous engineer improve over time.
Focused Evaluation Approach
The key to effective evaluation is focus. Handit uses single-purpose evaluators that examine one specific quality dimension at a time.
Example evaluators:
- Completeness: “Does the response address all parts of the question?”
- Accuracy: “Is the information factually correct?”
- Empathy: “Does the response show understanding for the user’s situation?”
Best Practice: Create separate evaluators for each quality dimension. This provides actionable insights and enables your autonomous engineer to generate targeted fixes.
The result: When empathy scores drop, your autonomous engineer knows exactly what to focus on when generating improvements.
Supported Models
OpenAI: GPT-4o (highest accuracy), GPT-3.5-turbo (cost-effective)
Together AI: Llama v4 Scout (open source), Llama v4 Maverick (high-volume)
Quick Setup
Time required: Under 5 minutes
Prerequisites: Node.js and a Handit.ai Account
Step 1: Install the CLI
npm install -g @handit.ai/cliStep 2: Configure evaluators
handit-cli evaluators-setupThe CLI will guide you through:
- Connect evaluation models (GPT-4, Llama, etc.)
- Configure evaluators for quality dimensions you care about
- Set evaluation percentages (how often to evaluate)
- Link to your AI components automatically
Setup complete! Your evaluation system is active. Quality scores will appear in your dashboard within minutes.
Verify setup
✅ Check your dashboard: Go to dashboard.handit.ai - you should see:
- Quality scores appearing for your AI interactions
- Evaluation trends in Agent Performance
- Individual interaction breakdowns
Understanding your evaluation data
Quality Monitoring: Your dashboard shows live evaluation scores as your AI processes requests, giving your autonomous engineer data to identify problems quickly.
Pattern Recognition: Your autonomous engineer analyzes quality patterns to understand when performance drops and what improvements would have the biggest impact.
Targeted Insights: Rather than generic scores, you see specific assessments across quality dimensions—completeness, accuracy, empathy—enabling targeted fixes.
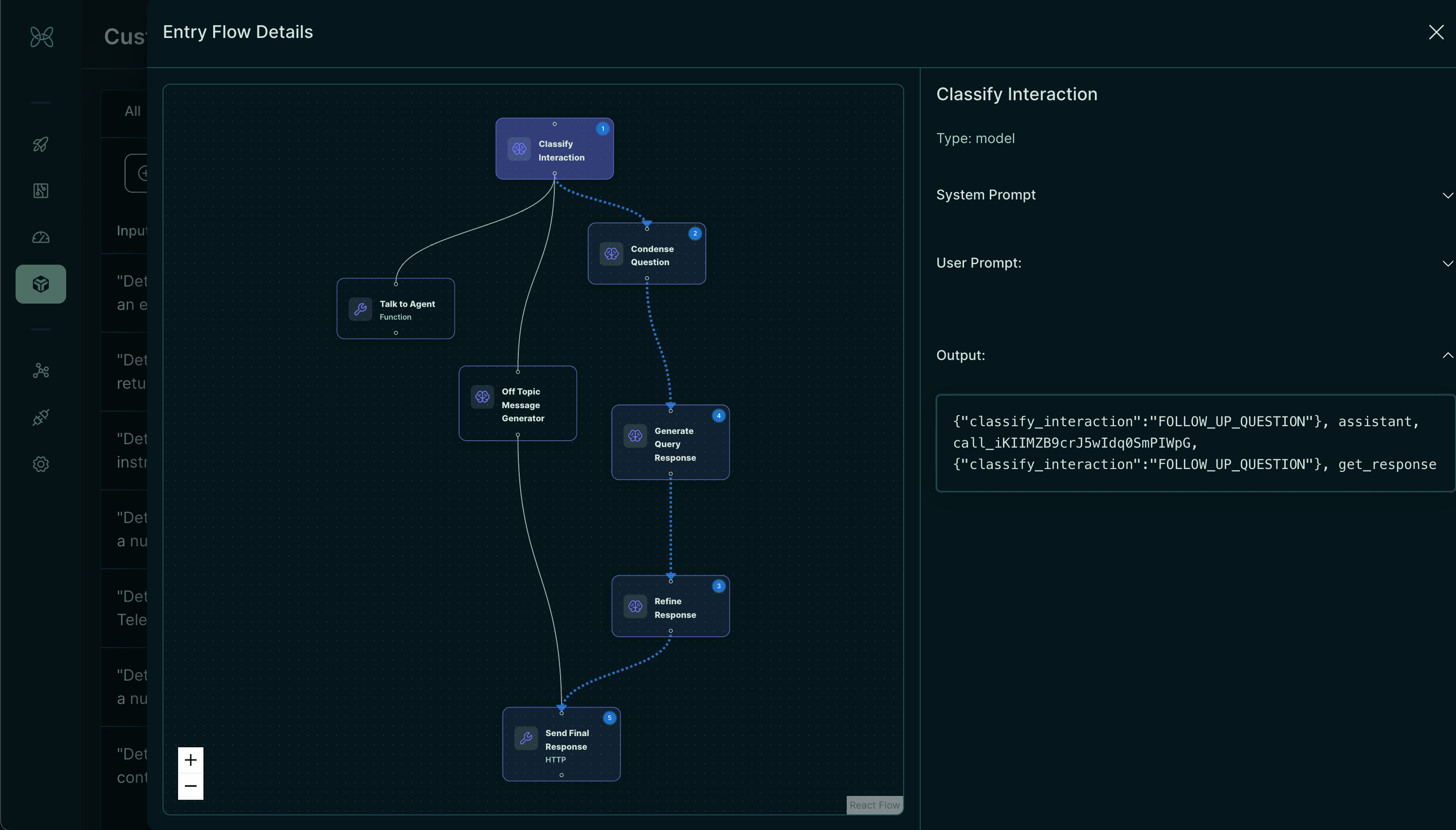
Next Steps
Complete Setup: For full autonomous engineer setup including monitoring and optimization, use our Complete Setup Guide.
Advanced Options:
- Custom Evaluators - Create quality assessments for your specific use case
- LLM as Judges - Advanced evaluation capabilities
Transform your AI quality control from manual spot-checking to autonomous monitoring and fixing.