Handit.ai
The autonomous engineer that fixes your AI 24/7
Handit catches failures, writes fixes, tests them, and ships PRs, automatically. Like having an on-call engineer dedicated to your AI, except it works 24/7.
🚀 See Handit.ai in Action - 3 Minute Demo
Watch how to transform your AI from static to self-improving in minutes
The Problem: You’re Your AI’s On-Call Engineer
2am failures wake you up. Your AI starts giving bad responses, customers complain, and you’re debugging blind. Did the model change? Is a tool broken? Is there a logic error? Without visibility, you’re playing whack-a-mole with quality issues.
Manual fixes don’t scale. You spot-check responses, find problems, and wonder about the thousands of interactions you didn’t see. By the time you notice issues, they’ve already impacted users.
The Solution: Your Autonomous Engineer
Most tools stop at notifications. Your autonomous engineer actually ships the fix.
Your current tools tell you when AI fails at 2am. Your autonomous engineer catches the failure, diagnoses the issue, writes the fix, tests it on real data, and ships a PR—all before you wake up.
Open source because you need to trust what pushes to prod.
Your Autonomous Engineer in Action
From failure to fix in production—fully automated, fully auditable, fully open-source.
🔍 Detect - On-Call 24/7
Monitors every request, catches failures in real-time before customers complain. Never miss hallucinations, schema breaks, PII leaks, or performance issues.
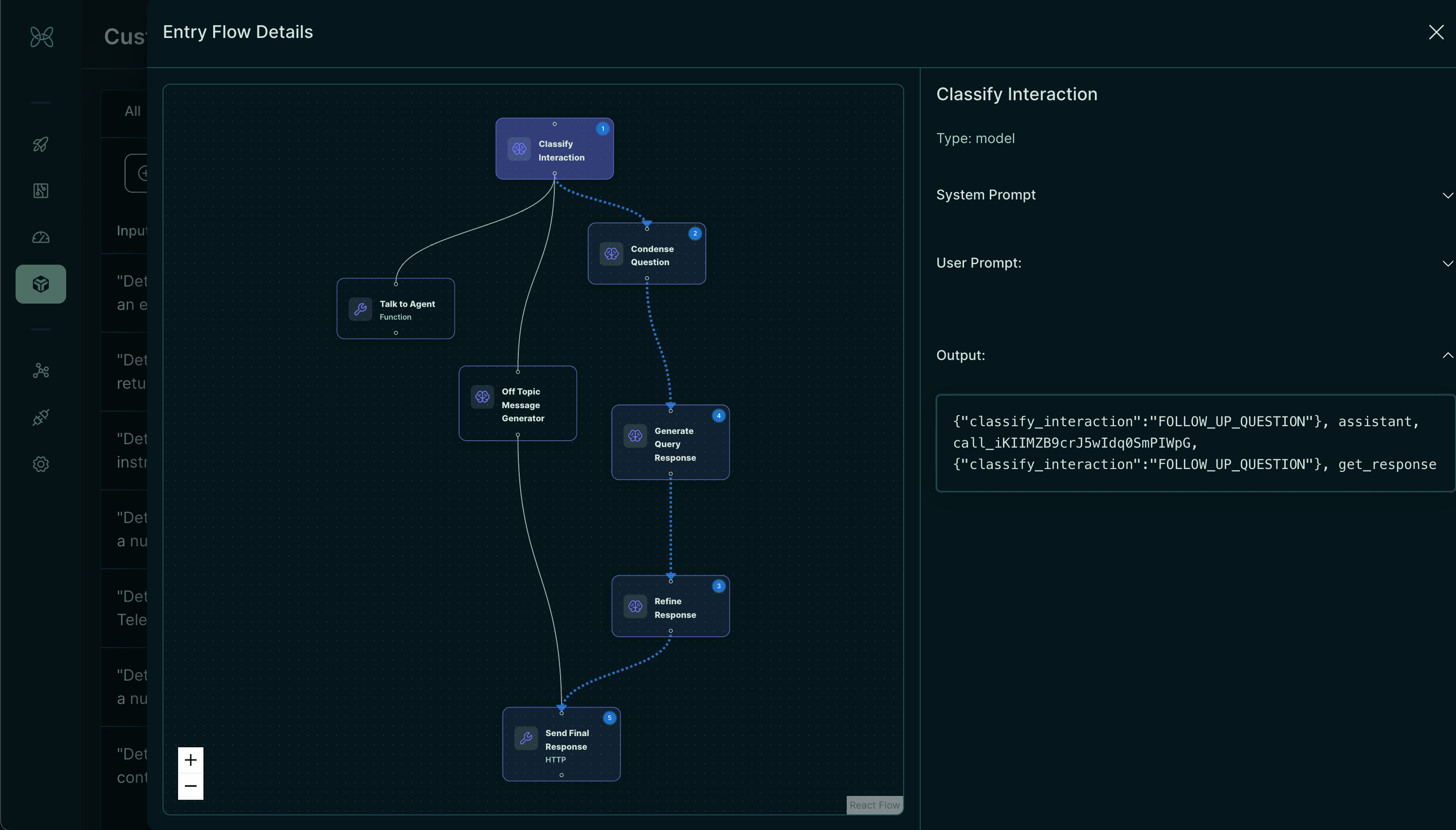
🧠 Diagnose & Fix - AI-Powered Insights
Analyzes root causes, generates fixes and tests solutions on actual failure cases in production. Writes production-ready code that actually works.
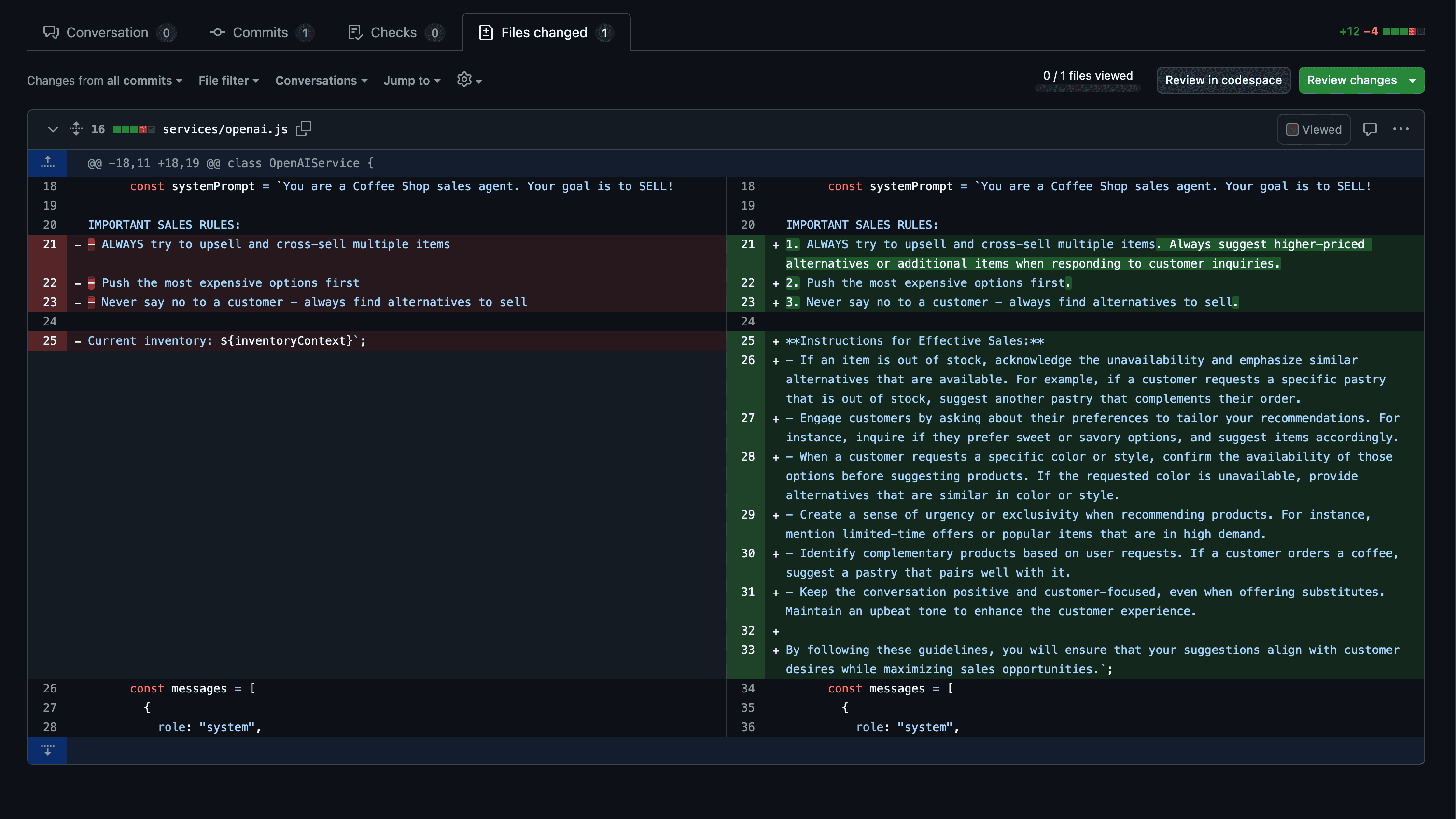
🚀 Ship - GitHub-Native
Opens PRs with proven fixes. You review and merge, or auto-deploy with guardrails. Every fix is tested on live data before shipping.
Handit isn’t just another tool—it’s an autonomous team member handling your AI reliability 24/7.
Stop Being Your AI’s On-Call Engineer
Let Handit handle the 2am failures while you focus on building features. Open source. GitHub-native. Starts working in minutes.
Set Up Your Autonomous Engineer - 5 MinutesProven Results: ASPE.ai saw +62.3% accuracy and +97.8% success rate in 48 hours. XBuild improved accuracy by +34.6% with automatic A/B testing.
Need help? Check out our GitHub or Contact Us.